




Researchers at DeepSeek on Monday released a new experimental model called V3.2-exp, designed to have dramatically lower inference costs when used in long-context operations. DeepSeek announced the model with a post on Hugging Face, also posting a linked academic paper on GitHub.
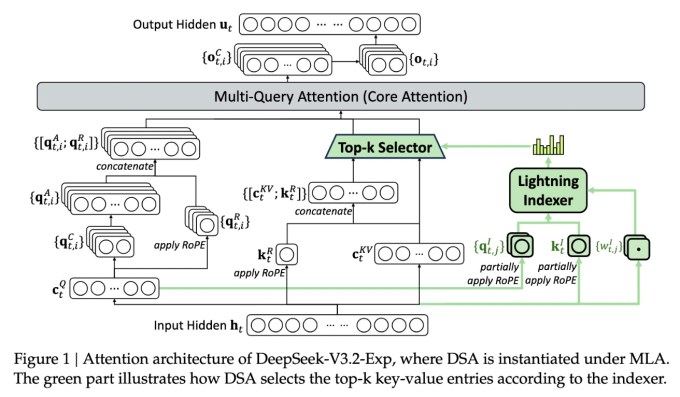
The most important feature of the new model is called DeepSeek Sparse Attention, an intricate system described in detail in the diagram below. In essence, the system uses a module called a “lightning indexer” to prioritize specific excerpts from the context window. After that, a separate system called a “fine-grained token selection system” chooses specific tokens from within those excerpts to load into the module’s limited attention window. Taken together, they allow the Sparse Attention models to operate over long portions of context with comparatively small server loads.
For long-context operations, the benefits of the system are significant. Preliminary testing by DeepSeek found that the price of a simple API call could be reduced by as much as half in long-context situations. Further testing will be required to build a more robust assessment, but because the model is open-weight and freely available on Hugging Face, it won’t be long before third-party tests can assess the claims made in the paper.
DeepSeek’s new model is one of a string of recent breakthroughs tackling the problem of inference costs — essentially, the server costs of operating a pre-trained AI model, as distinct from the cost of training it. In DeepSeek’s case, the researchers were looking for ways to make the fundamental transformer architecture operate more efficiently — and finding that there are significant improvements to be made.
Based in China, DeepSeek has been an unusual figure in the AI boom, particularly for those who view AI research as a nationalist struggle between the U.S. and China. The company made waves at the beginning of the year with its R1 model, trained using primarily reinforcement learning at a far lower cost than its American competitors. But the model has not sparked a wholesale revolution in AI training, as some predicted, and the company has receded from the spotlight in the months since.
The new “sparse attention” approach is unlikely to produce the same uproar as R1 — but it could still teach U.S. providers some much needed tricks to help keep inference costs low.
NUBBIN™ SHOP ᡣ𐭩ــــﮩ٨ـ






